 go语言开发
go语言开发
https://www.yuque.com/aceld/mo95lb/haizwm
# 一、引言

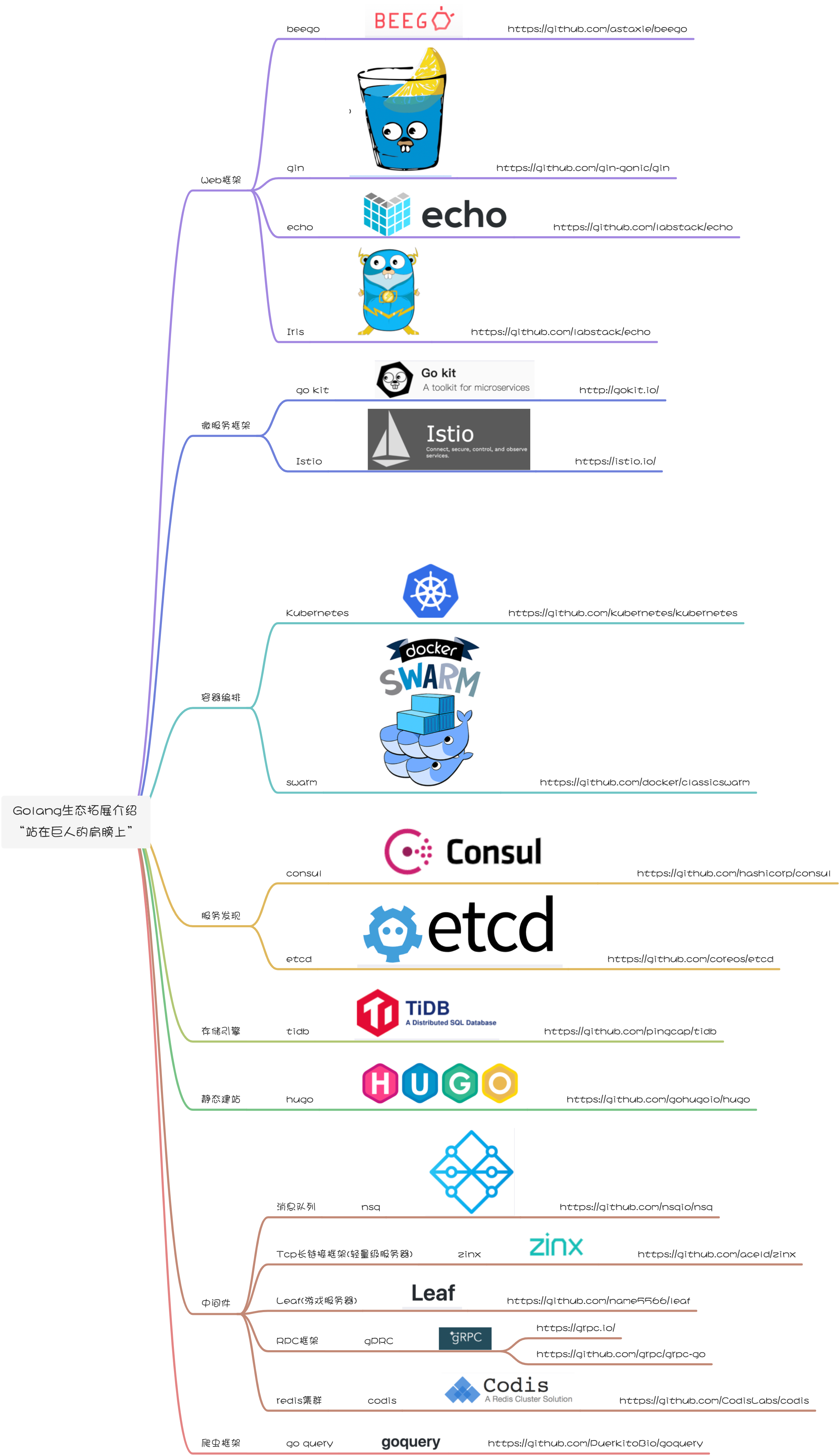
# Golang生态拓展介绍“站在巨人的肩膀上”
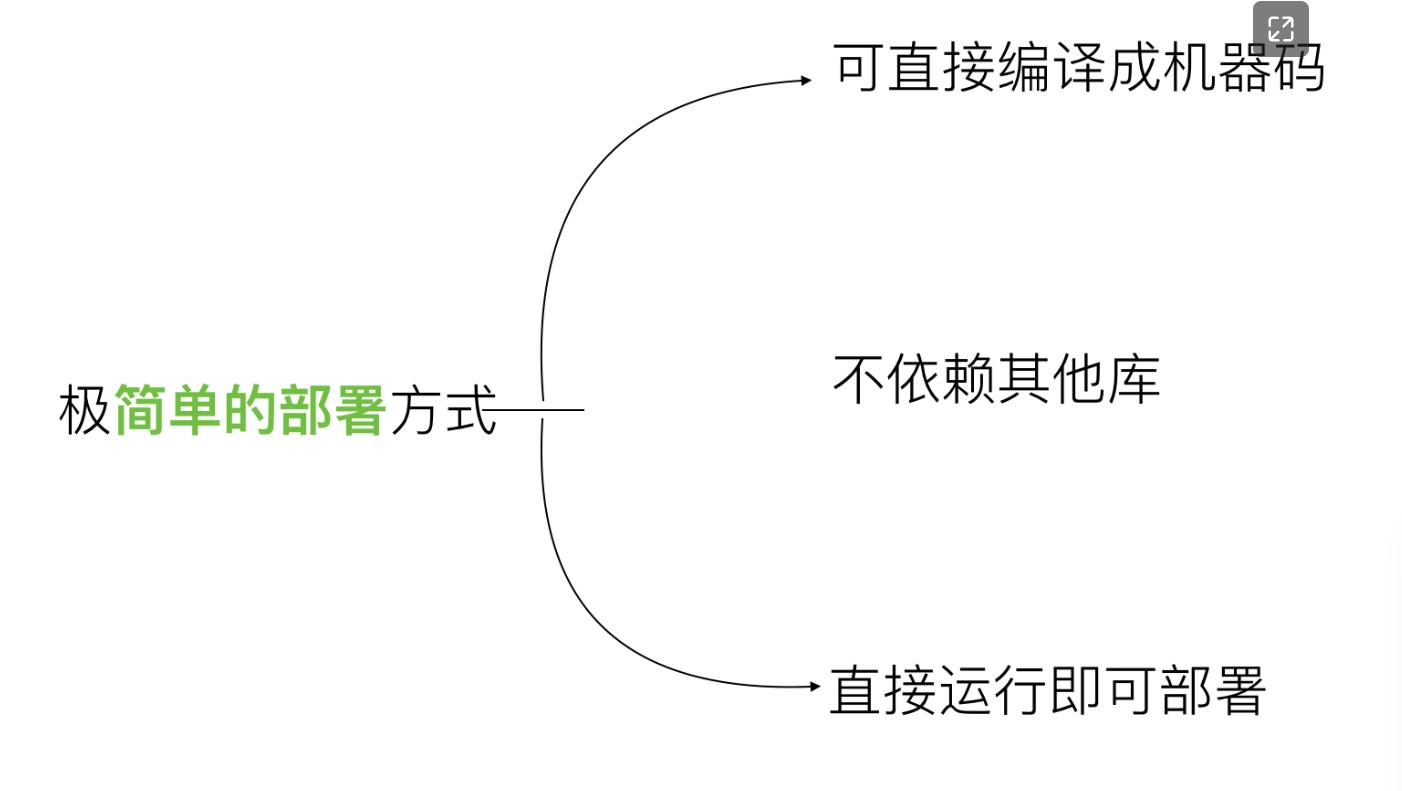
# 二、go开发环境
# GOPROXY
Go1.14版本之后,都推荐使用go mod模式来管理依赖了,也不再强制我们把代码必须写在GOPATH下面的src目录了,你可以在你电脑的任意位置编写go代码。
默认GoPROXY配置是:GOPROXY=https://proxy.golang.org,direct,
由于国内访问不到 https://proxy.golang.org 所以我们需要换一个PROXY,这里推荐使用https://goproxy.io 或 https://goproxy.cn。
可以执行下面的命令修改GOPROXY:
`go env -w GOPROXY=https://goproxy.cn,direct`
# 三、Golang语言特性
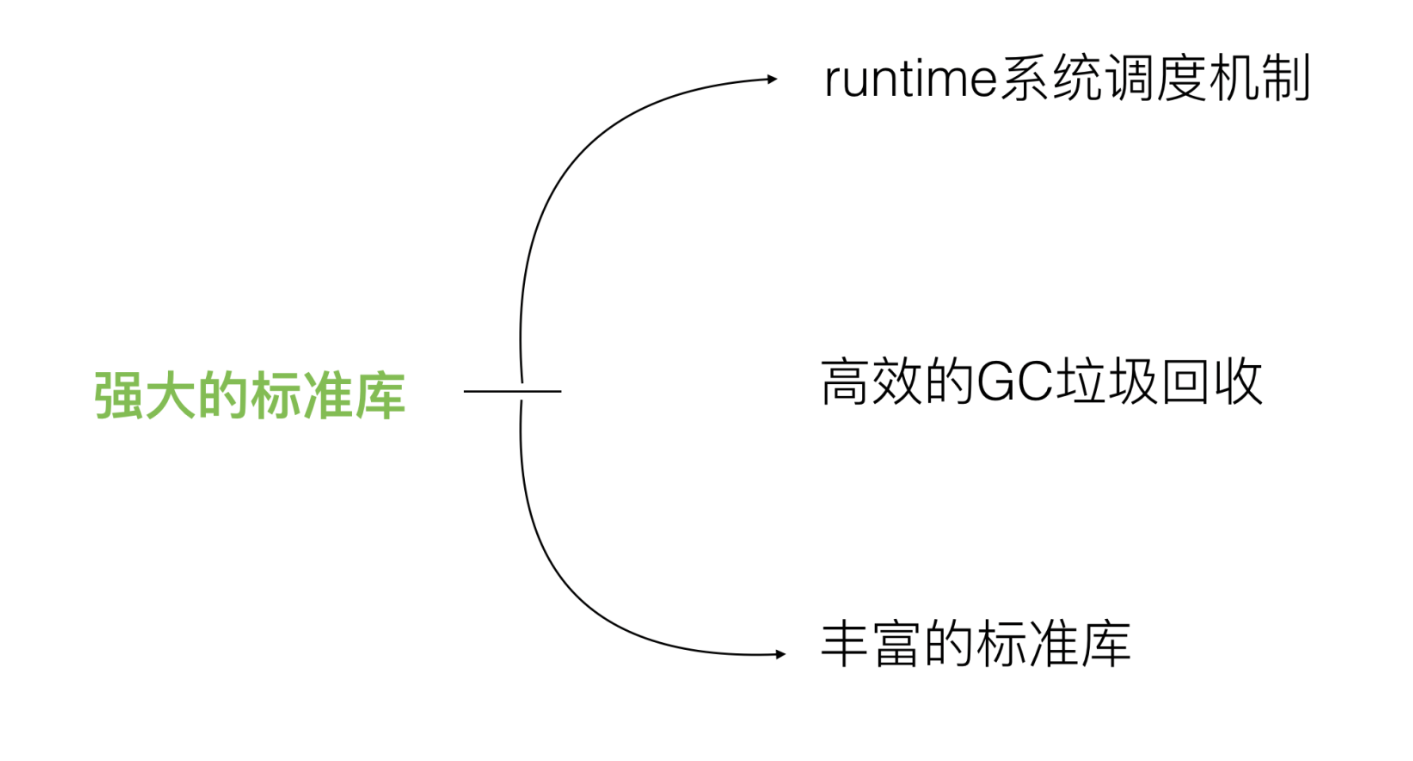
# Golang的优势

(和动态类型的js不同)
package main
import (
"fmt"
"time"
)
func goFunc(i int) {
fmt.Println("goroutine ", i, " ...")
}
func main() {
for i := 0; i < 10000; i++ {
go goFunc(i) //开启一个并发协程
}
time.Sleep(time.Second)
}
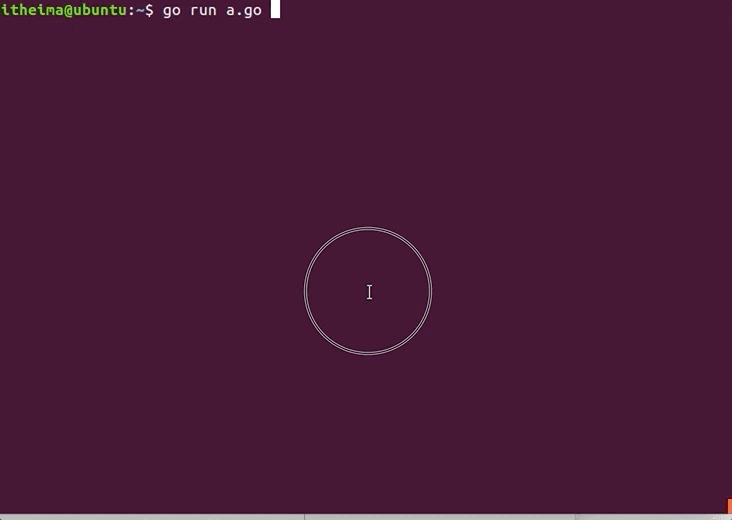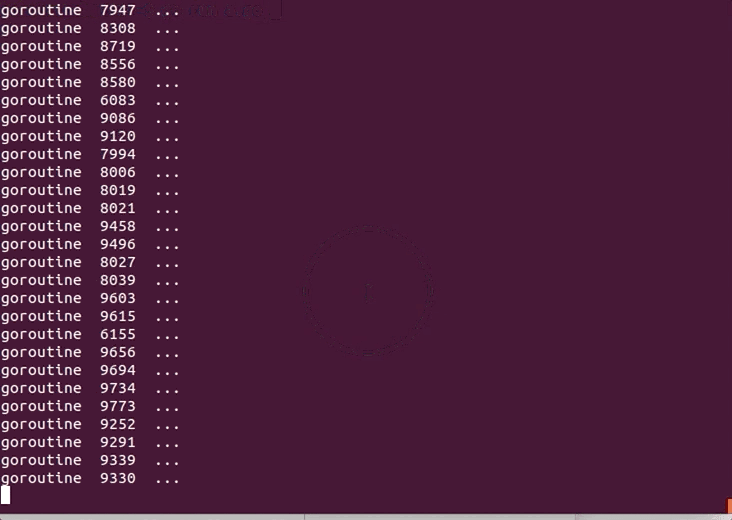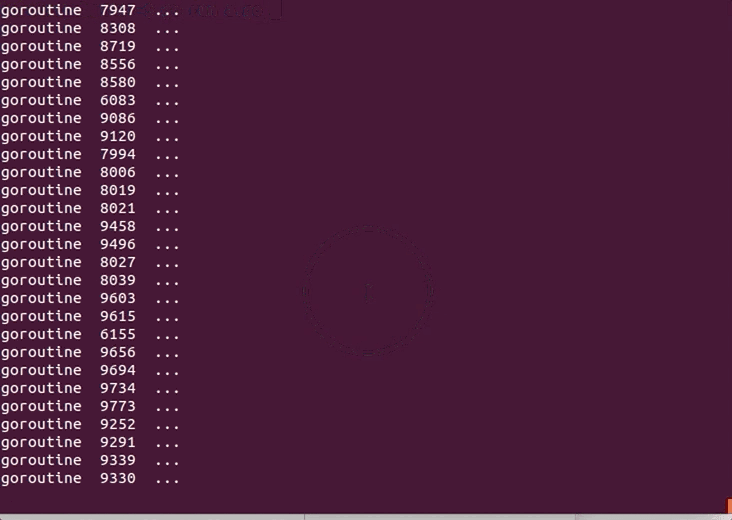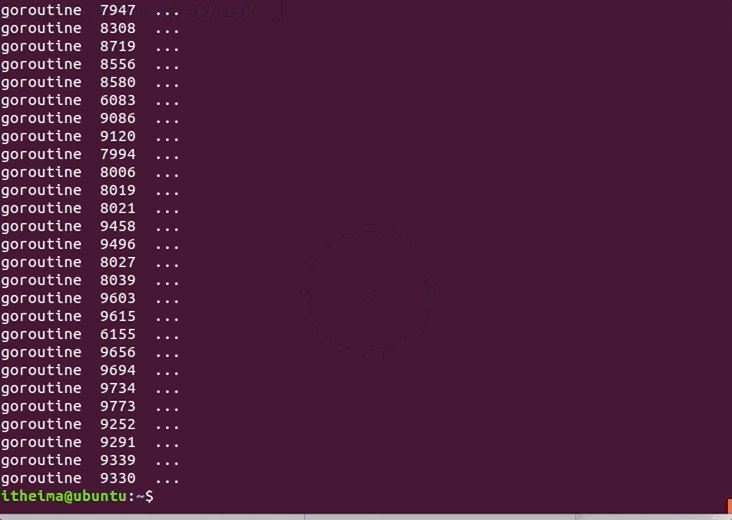

# Golang适合做什么
(1)、云计算基础设施领域
代表项目:docker、kubernetes、etcd、consul、cloudflare CDN、七牛云存储等。
(2)、基础后端软件
代表项目:tidb、influxdb、cockroachdb等。
(3)、微服务
代表项目:go-kit、micro、monzo bank的typhon、bilibili等。
(4)、互联网基础设施
代表项目:以太坊、hyperledger等。
# Golang明星作品



# Golang的不足
1、包管理,大部分包都在github上
2、无泛化类型
3、所有Excepiton都用Error来处理(比较有争议)。
4、对C的降级处理,并非无缝,没有C降级到asm那么完美(序列化问题)
# 四、Golang语法新奇
# main函数初见
package main
import "fmt"
func main() {
/* 简单的程序 万能的hello world */
fmt.Println("Hello Go")
}
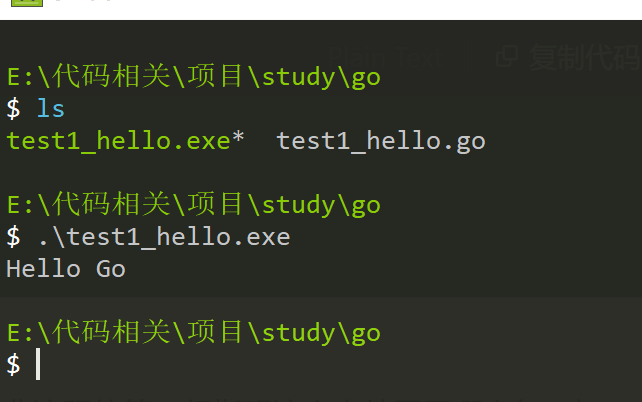
$ go run test1_hello.go
Hello Go
$
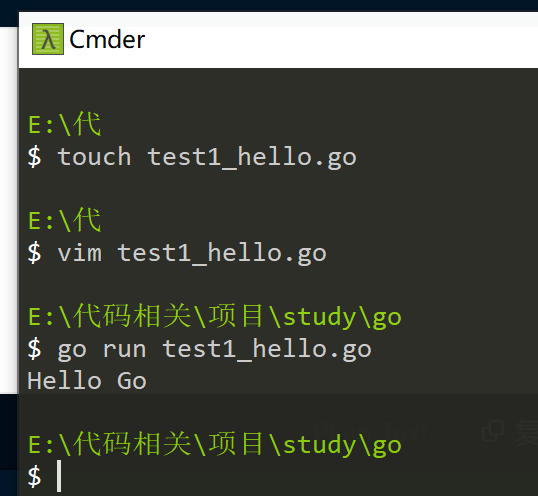
go run 表示 直接编译go语言并执行应用程序,一步完成
你也可以先编译,然后再执行
- 第一行代码package main定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
- 下一行**import "fmt"**告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。
- 下一行func main()是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
注意:这里面go语言的语法,定义函数的时候,‘{’ 必须和函数名在同一行,不能另起一行。(这个按照java的规范就ok了)
- 下一行 /.../ 是注释,在程序执行时将被忽略。单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 / 开头,并以 / 结尾,且不可以嵌套使用,多行注释一般用于包的文档描述或注释成块的代码片段。
- 下一行fmt.Println(...)可以将字符串输出到控制台,并在最后自动增加换行字符 \n。 使用 fmt.Print("hello, world\n") 可以得到相同的结果。 Print 和 Println 这两个函数也支持使用变量,如:fmt.Println(arr)。如果没有特别指定,它们会以默认的打印格式将变量 arr 输出到控制台。
# 变量的声明
声明变量的一般形式是使用 var 关键字
变量声明
第一种,指定变量类型,声明后若不赋值,使用默认值0。(不赋值的话,实际上就是js的声明方式再加上type约束)
var v_name v_type
v_name = value
package main
import "fmt"
func main() {
var a int
fmt.Printf(" = %d\n", a)
}
$go run test.go
a = 0
第二种,根据值自行判定变量类型。
var v_name = value
第三种,省略var, 注意 :=左侧的变量不应该是已经声明过的,否则会导致编译错误。
:=声明 go语言特产
v_name := value
// 例如
var a int = 10
var b = 10
c : = 10
例如:
package main
import "fmt"
func main() {
//第一种 使用默认值
var a int
fmt.Printf("a = %d\n", a)
//第二种
var b int = 10
fmt.Printf("b = %d\n", b)
//第三种 省略后面的数据类型,自动匹配类型
var c = 20
fmt.Printf("c = %d\n", c)
//第四种 省略var关键字
d := 3.14
fmt.Printf("d = %f\n", d)
}
# 多变量声明:
var(
a int
b bool
)
这种写法多用于全局变量声明。并且注意中间不需要加”,“或者”;“只需要换行就好了,然后注意到,go语言好像就不需要写";"
package main
import "fmt"
var x, y int
var ( //这种分解的写法,一般用于声明全局变量
a int
b bool
)
var c, d int = 1, 2
var e, f = 123, "liudanbing"
//这种不带声明格式的只能在函数体内声明
//g, h := 123, "需要在func函数体内实现"
func main() {
g, h := 123, "需要在func函数体内实现"
fmt.Println(x, y, a, b, c, d, e, f, g, h)
//不能对g变量再次做初始化声明
//g := 400
_, value := 7, 5 //实际上7的赋值被废弃,变量 _ 不具备读特性
//fmt.Println(_) //_变量的是读不出来的
fmt.Println(value) //5
}
这样的写法就和python很像了!
# 常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量的定义格式:
const identifier [type] = value
你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义:
const b string = "abc"
- 隐式类型定义:
const b = "abc"
例如:
package main
import "fmt"
func main() {
const LENGTH int = 10
const WIDTH int = 5
var area int
const a, b, c = 1, false, "str" //多重赋值
area = LENGTH * WIDTH
fmt.Printf("面积为 : %d\n", area)
println(a, b, c)
}
以上实例运行结果为:
面积为 : 50
1 false str
常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
数字 0、1 和 2 分别代表未知性别、女性和男性。
常量可以用len(), cap(), unsafe.Sizeof()常量计算表达式的值。常量表达式中,函数必须是内置函数,否则编译不过:
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main(){
println(a, b, c)
}
输出结果为:abc, 3, 16
unsafe.Sizeof(a)输出的结果是16 。
字符串类型在 go 里是个结构, 包含指向底层数组的指针和长度,这两部分每部分都是 8 个字节,所以字符串类型大小为 16 个字节。
# 优雅的常量 iota
有些概念有名字,并且有时候我们关注这些名字,甚至(特别)是在我们代码中。
const (
CCVisa = "Visa"
CCMasterCard = "MasterCard"
CCAmericanExpress = "American Express"
)
在其他时候,我们仅仅关注能把一个东西与其他的做区分。有些时候,有些时候一件事没有本质上的意义。比如,我们在一个数据库表中存储产品,我们可能不想以 string 存储他们的分类。我们不关注这个分类是怎样命名的,此外,该名字在市场上一直在变化。
我们仅仅关注它们是怎么彼此区分的。
const (
CategoryBooks = 0
CategoryHealth = 1
CategoryClothing = 2
)
使用 0, 1, 和 2 代替,我们也可以选择 17, 43, 和 61。这些值是任意的。
在 Go,常量有许多微妙之处。当用好了,可以使得代码非常优雅且易维护的。
# 自增长
在 golang 中,一个方便的习惯就是使用iota标示符,它简化了常量用于增长数字的定义,给以上相同的值以准确的分类。
const (
CategoryBooks = iota // 0
CategoryHealth // 1
CategoryClothing // 2
)
(可能这种写法比较优雅吧)
# iota和表达式
iota可以做更多事情,而不仅仅是 increment。更精确地说,iota总是用于 increment,但是它可以用于表达式,在常量中的存储结果值。
type Allergen int
const (
IgEggs Allergen = 1 << iota // 1 << 0 which is 00000001
IgChocolate // 1 << 1 which is 00000010
IgNuts // 1 << 2 which is 00000100
IgStrawberries // 1 << 3 which is 00001000
IgShellfish // 1 << 4 which is 00010000
)
(常量的声明中运用了iota放在表达式的写法,实际上在这个一行行声明的过程中,iota在increment,并且其它的常量都遵循这个表达式的规则。于是常量中实际存的式表达式的结果值)
(iota的自增性质用于区分概念常量)
这个工作是因为当你在一个const组中仅仅有一个标示符在一行的时候,它将使用增长的iota取得前面的表达式并且再运用它,。在 Go 语言的spec (opens new window)中, 这就是所谓的隐性重复最后一个非空的表达式列表.
如果你对鸡蛋,巧克力和海鲜过敏,把这些 bits 翻转到 “on” 的位置(从左到右映射 bits)。然后你将得到一个 bit 值00010011,它对应十进制的 19。
fmt.Println(IgEggs | IgChocolate | IgShellfish)
// output:
// 19
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
当你在把两个常量定义在一行的时候会发生什么?
Banana 的值是什么? 2 还是 3? Durian 的值又是?
const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
在下一行增长,而不是立即取得它的引用。(这里说明引用的概念是可以套用的)
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
(iota是编译器编译的时候是按照行自增规则来的)
# 函数
# 函数返回多个值
Go 函数可以返回多个值,例如:
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("Mahesh", "Kumar")
fmt.Println(a, b)
}
以上实例执行结果为:
Kumar Mahesh
(这个swap的写法讲实话还是挺骚的。。。)
(这个写法py好像也能写)
# init函数与import
首先我们看一个例子:init函数:
init 函数可在package main中,可在其他package中,可在同一个package中出现多次。
main函数
main 函数只能在package main中。
执行顺序
golang里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。这两个函数在定义时不能有任何的参数和返回值。
虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package main就必须包含一个main函数。
程序的初始化和执行都起始于main包。
如果main包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。
当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。
等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:
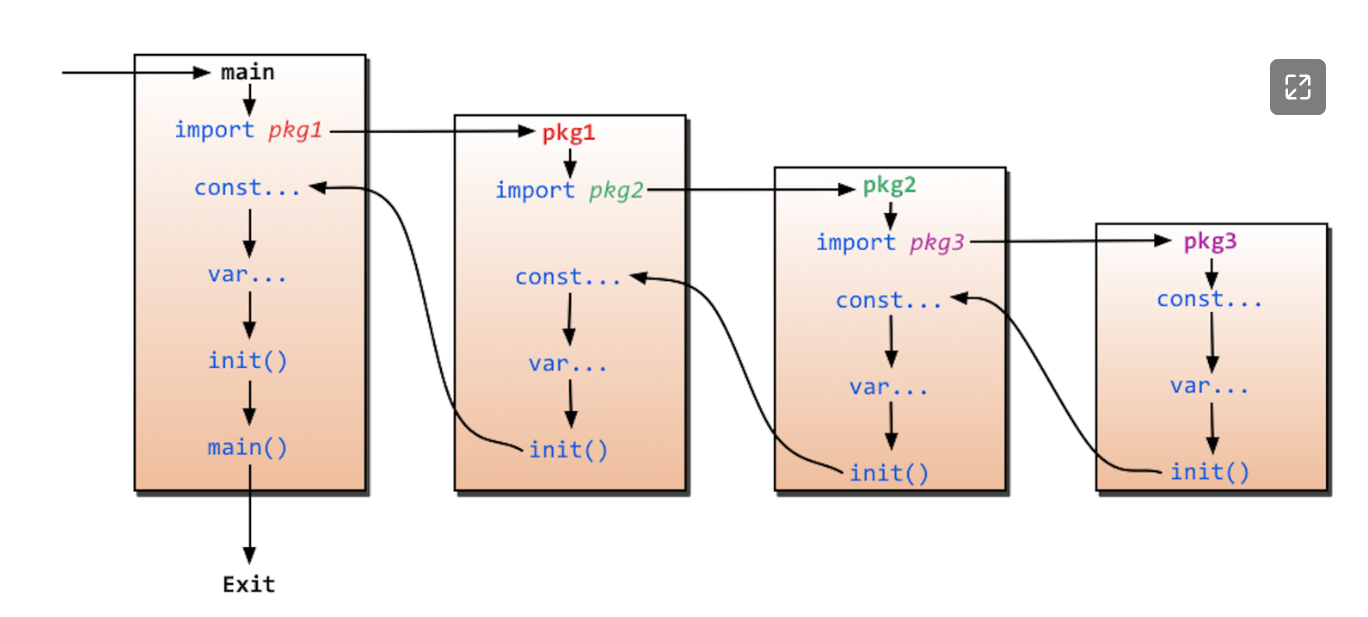
(包管理的概念,这个跟nodejs是一样的。Java的Spring则是用的ioc容器。)
除了main包是执行完import然后是声明式然后执行init()->main()函数的逻辑
其它的包都是执行完import然后是声明式然后是init()
(这里的init()如果在nodeJS的概念中有可能是go自动调用的export?)
首先我们看一个例子:
代码结构:
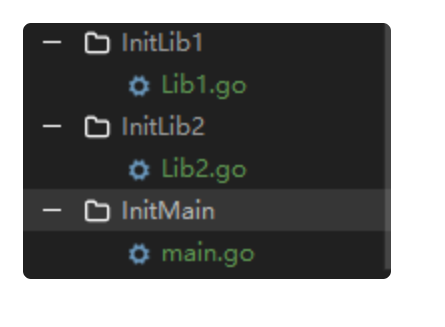
Lib1.go
package InitLib1
import "fmt"
func init() {
fmt.Println("lib1")
}
Lib2.go
package InitLib2
import "fmt"
func init() {
fmt.Println("lib2")
}
main.go
package main
import (
"fmt"
_ "GolangTraining/InitLib1"
_ "GolangTraining/InitLib2"
)
func init() {
fmt.Println("libmain init")
}
func main() {
fmt.Println("libmian main")
}
代码很简单,只是一些简单的输出
lib1
lib2
libmain init
libmian main
输出的顺序与我们上面图给出的顺序是一致的
那我们现在就改动一个地方,Lib1包导入Lib2,main包不管
package InitLib1
import (
"fmt"
_ "GolangTraining/InitLib2"
)
func init() {
fmt.Println("lib1")
}
输出:
lib2
lib1
libmain init
libmian main
main包以及Lib1包都导入了Lib2,但是只出现一次,并且最先输出,
==说明如果一个包会被多个包同时导入,那么它只会被导入一次,而先输出lib2是因为main包中导入Lib1时,Lib1又导入了Lib2,会首先初始化Lib2包的东西==
# 函数参数
函数如果使用参数,该变量可称为函数的形参。
形参就像定义在函数体内的局部变量。
调用函数,可以通过两种方式来传递参数:
# 值传递
值传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
(Java中只有值传递,只是对象(的引用)作为参数的时候传递过去的值是地址值,然后函数形参本身和对象(的引用)的地位相同,接受它的值,然后实际也是得到了对象的引用。我习惯理解成引用也是对象,值存的就是真实对象的地址值。
而放到基本类型(包括String)来看就没这么麻烦了,就是传值(普遍意义上的)而已(传递了值得拷贝)
)
以下定义了 swap() 函数:
/* 定义相互交换值的函数 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 将 y 值赋给 x */
y = temp /* 将 temp 值赋给 y*/
return temp;
}
接下来,让我们使用值传递来调用 swap() 函数:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
fmt.Printf("交换前 a 的值为 : %d\n", a )
fmt.Printf("交换前 b 的值为 : %d\n", b )
/* 通过调用函数来交换值 */
swap(a, b)
fmt.Printf("交换后 a 的值 : %d\n", a )
fmt.Printf("交换后 b 的值 : %d\n", b )
}
/* 定义相互交换值的函数 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 将 y 值赋给 x */
y = temp /* 将 temp 值赋给 y*/
return temp;
}
以下代码执行结果为:
交换前 a 的值为 : 100
交换前 b 的值为 : 200
交换后 a 的值 : 100
交换后 b 的值 : 200
# 引用传递(指针传递)
指针
Go 语言中指针是很容易学习的,Go 语言中使用指针可以更简单的执行一些任务。
接下来让我们来一步步学习 Go 语言指针。
我们都知道,变量是一种使用方便的占位符,用于引用计算机内存地址。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
以下实例演示了变量在内存中地址:
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("变量的地址: %x\n", &a )
}
执行以上代码输出结果为:
变量的地址: 20818a220
现在我们已经了解了什么是内存地址和如何去访问它。接下来我们将具体介绍指针。
引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
引用传递指针参数传递到函数内,以下是交换函数 swap() 使用了引用传递:
/* 定义交换值函数*/
func swap(x *int, y *int) {
var temp int
temp = *x /* 保持 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
以下我们通过使用引用传递来调用 swap() 函数:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int= 200
fmt.Printf("交换前,a 的值 : %d\n", a )
fmt.Printf("交换前,b 的值 : %d\n", b )
/* 调用 swap() 函数
* &a 指向 a 指针,a 变量的地址
* &b 指向 b 指针,b 变量的地址
*/
swap(&a, &b)
fmt.Printf("交换后,a 的值 : %d\n", a )
fmt.Printf("交换后,b 的值 : %d\n", b )
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
(Java中由于只有传值,所以想做到和它们这种支持传址(传引用)的语言相比就麻烦些。需要用到数组等对象辅助)
(传值就是形参获取实参的值的拷贝。传址就是形参获取实参的地址,直接对地址操作)
//交换两个整数
private static void swap(int[] source, int i, int j) {
int temp = source[i];
source[i] = source[j];
source[j] = temp;
}
# 匿名函数和闭包
详细解释:
在Go语言中匿名函数和闭包是一个概念:
闭包是可以包含自由(未绑定到特定对象)变量的代码块,这些变量不在这个代码块内或者 任何全局上下文中定义,而是在定义代码块的环境中定义。要执行的代码块(由于自由变量包含 在代码块中,所以这些自由变量以及它们引用的对象没有被释放)为自由变量提供绑定的计算环 境(作用域)。
闭包的价值: 闭包的价值在于可以作为函数对象或者匿名函数,对于类型系统而言,这意味着不仅要表示 数据还要表示代码。支持闭包的多数语言都将函数作为第一级对象,就是说这些函数可以存储到 变量中作为参数传递给其他函数,最重要的是能够被函数动态创建和返回。(总的来说就是可以使用匿名函数返回,匿名函数层层依赖到外面的变量)
Go语言中的闭包同样也会引用到函数外的变量。闭包的实现确保只要闭包还被使用,那么被闭包引用的变量会一直存在。
例子:
Go 函数可以是一个闭包。闭包是一个函数值(就是return的那个玩意),它引用了其函数体之外的变量(adder()中的sum)。该函数可以访问并赋予其引用的变量的值(sum),换句话说,该函数(匿名的函数)被这些变量(sum)“绑定”在一起。
例如,函数 adder 返回一个闭包。每个闭包都被绑定在其各自的 sum 变量上。
package main
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}import "fmt"
这里就可以很好的理解我们刚才的解释了,在函数addr()中,sum这个变量就被”包“在了另一个匿名函数中了。这个匿名函数就是我们上面的自由变量的概念。
# slice和map
==Go 语言切片是对数组的抽象。==
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
# 定义切片
你可以声明一个未指定大小的数组来定义切片:
var identifier []type
切片不需要说明长度。
或使用make()函数来创建切片:
var slice1 []type = make([]type, len)
也可以简写为
slice1 := make([]type, len)
也可以指定容量,其中capacity为可选参数。
make([]T, length, capacity)
这里 len 是数组的长度并且也是切片的初始长度。
# 切片初始化
s :=[] int {1,2,3 }
直接初始化切片,[]表示是切片类型,{1,2,3}初始化值依次是1,2,3.其cap=len=3
s := arr[:]
初始化切片s,是数组arr的引用
s := arr[startIndex:endIndex]
将arr中从下标startIndex到endIndex-1 下的元素创建为一个新的切片
s := arr[startIndex:]
缺省endIndex时将表示一直到arr的最后一个元素
s := arr[:endIndex]
缺省startIndex时将表示从arr的第一个元素开始
s1 := s[startIndex:endIndex]
通过切片s初始化切片s1
s :=make([]int,len,cap)
通过内置函数make()初始化切片s,[]int 标识为其元素类型为int的切片
# len() 和 cap() 函数
切片是可索引的,并且可以由 len() 方法获取长度。
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
以下为具体实例:
package main
import "fmt"
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
以上实例运行输出结果为:
len=3 cap=5 slice=[0 0 0]
# 空(nil)切片
一个切片在未初始化之前默认为 nil,长度为 0,实例如下:
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
if(numbers == nil){
fmt.Printf("切片是空的")
}
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
以上实例运行输出结果为:
len=0 cap=0 slice=[]
切片是空的
# 切片截取
可以通过设置下限及上限来设置截取切片*[lower-bound:upper-bound]*,实例如下:
package main
import "fmt"
func main() {
/* 创建切片 */
numbers := []int{0,1,2,3,4,5,6,7,8}
printSlice(numbers)
/* 打印原始切片 */
fmt.Println("numbers ==", numbers)
/* 打印子切片从索引1(包含) 到索引4(不包含)*/
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* 默认下限为 0*/
fmt.Println("numbers[:3] ==", numbers[:3])
/* 默认上限为 len(s)*/
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int,0,5)
printSlice(numbers1)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */
number2 := numbers[:2]
printSlice(number2)
/* 打印子切片从索引 2(包含) 到索引 5(不包含) */
number3 := numbers[2:5]
printSlice(number3)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
执行以上代码输出结果为:
len=9 cap=9 slice=[0 1 2 3 4 5 6 7 8]
numbers == [0 1 2 3 4 5 6 7 8]
numbers[1:4] == [1 2 3]
numbers[:3] == [0 1 2]
numbers[4:] == [4 5 6 7 8]
len=0 cap=5 slice=[]
len=2 cap=9 slice=[0 1]
len=3 cap=7 slice=[2 3 4]
# append() 和 copy() 函数
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。
下面的代码描述了从拷贝切片的 copy 方法和向切片追加新元素的 append 方法。
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
/* 允许追加空切片 */
numbers = append(numbers, 0)
printSlice(numbers)
/* 向切片添加一个元素 */
numbers = append(numbers, 1)
printSlice(numbers)
/* 同时添加多个元素 */
numbers = append(numbers, 2,3,4)
printSlice(numbers)
/* 创建切片 numbers1 是之前切片的两倍容量*/
numbers1 := make([]int, len(numbers), (cap(numbers))*2)
/* 拷贝 numbers 的内容到 numbers1 */
copy(numbers1,numbers)
printSlice(numbers1)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
以上代码执行输出结果为:
len=0 cap=0 slice=[]
len=1 cap=1 slice=[0]
len=2 cap=2 slice=[0 1]
len=5 cap=6 slice=[0 1 2 3 4]
len=5 cap=12 slice=[0 1 2 3 4]
# map
map和slice类似,只不过是数据结构不同,下面是map的一些声明方式。
package main
import (
"fmt"
)
func main() {
//第一种声明
var test1 map[string]string
//在使用map前,需要先make,make的作用就是给map分配数据空间
test1 = make(map[string]string, 10)
test1["one"] = "php"
test1["two"] = "golang"
test1["three"] = "java"
fmt.Println(test1) //map[two:golang three:java one:php]
//第二种声明
test2 := make(map[string]string)
test2["one"] = "php"
test2["two"] = "golang"
test2["three"] = "java"
fmt.Println(test2) //map[one:php two:golang three:java]
//第三种声明
test3 := map[string]string{
"one" : "php",
"two" : "golang",
"three" : "java",
}
fmt.Println(test3) //map[one:php two:golang three:java]
language := make(map[string]map[string]string)
language["php"] = make(map[string]string, 2)
language["php"]["id"] = "1"
language["php"]["desc"] = "php是世界上最美的语言"
language["golang"] = make(map[string]string, 2)
language["golang"]["id"] = "2"
language["golang"]["desc"] = "golang抗并发非常good"
fmt.Println(language) //map[php:map[id:1 desc:php是世界上最美的语言] golang:map[id:2 desc:golang抗并发非常good]]
//增删改查
// val, key := language["php"] //查找是否有php这个子元素
// if key {
// fmt.Printf("%v", val)
// } else {
// fmt.Printf("no");
// }
//language["php"]["id"] = "3" //修改了php子元素的id值
//language["php"]["nickname"] = "啪啪啪" //增加php元素里的nickname值
//delete(language, "php") //删除了php子元素
fmt.Println(language)
}
# 面向对象的特征
# 方法
假设有两个方法,一个方法的接收者是指针类型,一个方法的接收者是值类型,那么:
- 对于值类型的变量和指针类型的变量,这两个方法有什么区别?
- 如果这两个方法是为了实现一个接口,那么这两个方法都可以调用吗?
- 如果方法是嵌入到其他结构体中的,那么上面两种情况又是怎样的?
package main
import "fmt"
//定义一个结构体
type T struct {
name string
}
func (t T) method1() {
t.name = "new name1"
}
func (t *T) method2() {
t.name = "new name2"
}
func main() {
t := T{"old name"}
fmt.Println("method1 调用前 ", t.name)
t.method1()
fmt.Println("method1 调用后 ", t.name)
fmt.Println("method2 调用前 ", t.name)
t.method2()
fmt.Println("method2 调用后 ", t.name)
}
method1 调用前 old name
method1 调用后 old name
method2 调用前 old name
method2 调用后 new name2
当调用t.method1()时相当于method1(t),实参和行参都是类型 T,可以接受。此时在method1()中的t只是参数t的值拷贝,所以method1()的修改影响不到main中的t变量。
当调用t.method2()=>method2(t),这是将 T 类型传给了 *T 类型,go可能会取 t 的地址传进去:method2(&t)。所以 method1() 的修改可以影响 t。
T 类型的变量这两个方法都是拥有的。
# 心法
(这里想用Java的方式理解可能会比较困难。毕竟go和js的自定义类一样都是不被class结构给约束的,这里可以看出,正常的成员变量声明还是放在结构里面的。然后方法参考js,对象是通过原型,直接无中生有一个引用来接收方法对象。所以实际上我们可以想到只要给了方法类型的对象的地址就好了,这样就能操作对象里面的成员了。怎么个给法就是语法问题。==所以感觉golang编程的时候不用太关心类和对象的概念,只需要清楚你想达到这种效果需要什么条件,然后按照语法把条件给它,最后达到的效果实际上每个语言都是一样的==)
(==然后这里点名表扬一下java是可以做到完全带着概念编程的==)
# 方法值和方法表达式
# 方法值
我们经常选择一个方法,并且在同一个表达式里执行,比如常见的p.Distance()形式,实际上将其分成两步来执行也是可能的。p.Distance叫作“选择器”,
选择器会返回一个方法"值"
一个将方法(Point.Distance)绑定到特定接收器变量的函数。
这个函数可以不通过指定其接收器即可被调用;即调用时不需要指定接收器,只要传入函数的参数即可:
package main
import "fmt"
import "math"
type Point struct{ X, Y float64 }
//这是给struct Point类型定义一个方法
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
func main() {
p := Point{1, 2}
q := Point{4, 6}
distanceFormP := p.Distance // 方法值(相当于C语言的函数地址,函数指针)
fmt.Println(distanceFormP(q)) // "5"
fmt.Println(p.Distance(q)) // "5"
//实际上distanceFormP 就绑定了 p接收器的方法Distance
distanceFormQ := q.Distance //
fmt.Println(distanceFormQ(p)) // "5"
fmt.Println(q.Distance(p)) // "5"
//实际上distanceFormQ 就绑定了 q接收器的方法Distance
}
在一个包的API需要一个函数值、且调用方希望操作的是某一个绑定了对象的方法的话,方法"值"会非常实用.
举例来说,下面例子中的time.AfterFunc这个函数的功能是在指定的延迟时间之后来执行一个(译注:另外的)函数。且这个函数操作的是一个Rocket对象r
type Rocket struct { /* ... */ }
func (r *Rocket) Launch() { /* ... */ }
r := new(Rocket)
time.AfterFunc(10 * time.Second, func() { r.Launch() })
直接用方法"值"传入AfterFunc的话可以更为简短:
time.AfterFunc(10 * time.Second, r.Launch)
省掉了上面那个例子里的匿名函数。
(嘛,这个方法"值"的概念感觉吹的有点花哨了,实际上就是可以理解成是方法对象嘛,选择器不就是方法对象的引用名嘛,只是清楚这个选择器是主动自动返回方法"值"的就行)
# 方法表达式
和方法"值"相关的还有方法表达式。当调用一个方法时,与调用一个普通的函数相比,我们必须要用选择器(p.Distance)语法来指定方法的接收器。
当T是一个类型时,方法表达式可能会写作T.f或者(*T).f,会返回一个函数"值",这种函数会将其第一个参数用作接收器,所以可以用通常(译注:不写选择器)的方式来对其进行调用:
package main
import "fmt"
import "math"
type Point struct{ X, Y float64 }
//这是给struct Point类型定义一个方法
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
func main() {
p := Point{1, 2}
q := Point{4, 6}
distance1 := Point.Distance //方法表达式, 是一个函数值(相当于C语言的函数指针)
fmt.Println(distance1(p, q))
fmt.Printf("%T\n", distance1) //%T表示打出数据类型 ,这个必须放在Printf使用
distance2 := (*Point).Distance //方法表达式,必须传递指针类型
distance2(&p, q)
fmt.Printf("%T\n", distance2)
}
执行结果
5
func(main.Point, main.Point) float64
func(*main.Point, main.Point) float64
// 这个Distance实际上是指定了Point对象为接收器的一个方法func (p Point) Distance(),
// 但通过Point.Distance得到的函数需要比实际的Distance方法多一个参数,
// 即其需要用第一个额外参数指定接收器,后面排列Distance方法的参数。
// 看起来本书中函数和方法的区别是指有没有接收器,而不像其他语言那样是指有没有返回值。
当你根据一个变量来决定调用同一个类型的哪个函数时,方法表达式就显得很有用了。你可以根据选择来调用接收器各不相同的方法。下面的例子,变量op代表Point类型的addition或者subtraction方法,Path.TranslateBy方法会为其Path数组中的每一个Point来调用对应的方法:
package main
import "fmt"
import "math"
type Point struct{ X, Y float64 }
//这是给struct Point类型定义一个方法
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
func (p Point) Add(another Point) Point {
return Point{p.X + another.X, p.Y + another.Y}
}
func (p Point) Sub(another Point) Point {
return Point{p.X - another.X, p.Y - another.Y}
}
func (p Point) Print() {
fmt.Printf("{%f, %f}\n", p.X, p.Y)
}
//定义一个Point切片类型 Path
type Path []Point
//方法的接收器 是Path类型数据, 方法的选择器是TranslateBy(Point, bool)
func (path Path) TranslateBy(another Point, add bool) {
var op func(p, q Point) Point //定义一个 op变量 类型是方法表达式 能够接收Add,和 Sub方法
if add == true {
op = Point.Add //给op变量赋值为Add方法
} else {
op = Point.Sub //给op变量赋值为Sub方法
}
for i := range path {
//调用 path[i].Add(another) 或者 path[i].Sub(another)
path[i] = op(path[i], another)
path[i].Print()
}
}
func main() {
points := Path{
{10, 10},
{11, 11},
}
anotherPoint := Point{5, 5}
points.TranslateBy(anotherPoint, false)
fmt.Println("------------------")
points.TranslateBy(anotherPoint, true)
}
运行结果:
{5.000000, 5.000000}
{6.000000, 6.000000}
------------------
{10.000000, 10.000000}
{11.000000, 11.000000}
# 理清楚
Go 语言的方法非常纯粹, 可以看作特殊类型的函数, 其显式地将对象实例或指针作为函数的第一个参数, 并且参数名可以自己指定, 而不强制要求一定是 this 或 self 。这个对象实例或指针称为方法的接收者(reciever)。
(给方法找个归属,它是在哪个类里面的,哪个对象里面的。或者直接理解成方法的调用者就好了嘛,就是this的概念!只是可以写在前面,或者让编译器指定参数表中的第一个参数为这个角色)
为命名类型定义方法的语法格式如下:
// 类型方法接收者是值类型
func (t TypeName) MethodName (ParamList ) (Returnlist) {
//method body
}
// 类型方法接收者是指针
func (t *TypeName) MethodName (ParamList) (Returnlist) {
//method body
}
说明:
t 是接收者或者叫接收器变量,官方建议使用接收器类型名 TypeName 的 第一个小写字母,而不是 self 、 this 之类的命名。例如, Socket 类型的接收器变量应该命名为 s, Connector 类型的接收器变量应该命名为 c 等;
TypeName 为命名类型的类型名;
MethodName 为方法名,是一个自定义标识符;
ParamList 是形参列表;
ReturnList 是返回值列表;
接收者的定义和普通变量、函数参数等一样,前面是变量名,后面是接收者类型。
Go 方法实质上是以方法的 receiver 参数作为第一个参数的普通函数,没有使用隐式的指针,我们可以将类型的方法改写为常规的函数。示例如下:
//类型方法接收者是值类型
func TypName_MethodName(t TypeName , otherParamList) (Returnlist) {
//method body
}
//类型方法接收者是指针
func TypName_MethodName (t *TypeName , otherParamList) (Returnlist) {
//method body
}
# receiver可以使用指针
package main
import "fmt"
type MyStruct struct {
x int
}
func (m MyStruct) Set1() {
m.x = 1
}
func (m *MyStruct) Set2() {
m.x = 2
}
func main() {
s := MyStruct{x: 0}
s.Set1()
fmt.Println(s.x)
s.Set2()
fmt.Println(s.x)
}
输出
0
2
可以看出,Set1并没有修改值,Set2才修改了值,是因为指针receiver才是修改原来的值,否则只是复制变量出来成为函数里的局部变量
# 如何判断receiver是否要用指针
method的value receiver和pointer receiver怎么选择,官方说了2个原因来使用pointer receiver
- 需要修改原来的值
- 防止每次调用method时候都拷贝value,比如当struct很大的时候每次都拷贝value会降低效率
下面是我个人理解,不一定准确:
实际应用中,有一个情况是不能用pointer receiver:pointer可能造成安全风险,例如某个method只是要获取金额,而不是修改金额,那么使用pointer的话就存在当内存被泄露等情况导致金额被修改。
因此,若没有涉及性能问题,且method的功能是读,而非写的时候,首选value receiver
# interface与类型断言
Golang的语言中提供了断言的功能。golang中的所有程序都实现了interface{}的接口,这意味着,所有的类型如string,int,int64甚至是自定义的struct类型都就此拥有了interface{}的接口,这种做法和java中的Object类型比较类似。那么在一个数据通过func funcName(interface{})的方式传进来的时候,也就意味着这个参数被自动的转为interface{}的类型。
func funcName(a interface{}) string {
return string(a)
}
编译器会返回
cannot convert a (type interface{}) to type string: need type assertion
此时,意味着整个转化的过程需要类型断言。类型断言有以下几种形式:(其实就是类型转型)
1)直接断言使用
var a interface{}
fmt.Println("Where are you,Jonny?", a.(string))
但是如果断言失败一般会导致panic的发生。所以为了防止panic的发生,我们需要在断言前进行一定的判断
value, ok := a.(string)
如果断言失败,那么ok的值将会是false,但是如果断言成功ok的值将会是true,同时value将会得到所期待的正确的值。示例:
value, ok := a.(string)
if !ok {
fmt.Println("It's not ok for type string")
return
}
fmt.Println("The value is ", value)
完整例子如下:
package main
import "fmt"
/*
func funcName(a interface{}) string {
return string(a)
}
*/
func funcName(a interface{}) string {
value, ok := a.(string)
if !ok {
fmt.Println("It is not ok for type string")
return ""
}
fmt.Println("The value is ", value)
return value
}
func main() {
// str := "123"
// funcName(str)
//var a interface{}
//var a string = "123"
var a int = 10
funcName(a)
}
2)配合switch使用
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T", t) // %T prints whatever type t has
case bool:
fmt.Printf("boolean %t\n", t) // t has type bool
case int:
fmt.Printf("integer %d\n", t) // t has type int
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t has type *bool
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t has type *int
}
或者如下使用方法
func sqlQuote(x interface{}) string {
if x == nil {
return "NULL"
} else if _, ok := x.(int); ok {
return fmt.Sprintf("%d", x)
} else if _, ok := x.(uint); ok {
return fmt.Sprintf("%d", x)
} else if b, ok := x.(bool); ok {
if b {
return "TRUE"
}
return "FALSE"
} else if s, ok := x.(string); ok {
return sqlQuoteString(s) // (not shown)
} else {
panic(fmt.Sprintf("unexpected type %T: %v", x, x))
}
}
# 反射reflect
# 编程语言中反射的概念
在计算机科学领域,反射是指一类应用,它们能够自描述和自控制。也就是说,这类应用通过采用某种机制来实现对自己行为的描述(self-representation)和监测(examination),并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义。
每种语言的反射模型都不同,并且有些语言根本不支持反射。Golang语言实现了反射,反射机制就是在运行时动态的调用对象的方法和属性,官方自带的reflect包就是反射相关的,只要包含这个包就可以使用。
多插一句,Golang的gRPC也是通过反射实现的。
# interface 和 反射
在讲反射之前,先来看看Golang关于类型设计的一些原则
- 变量包括(type, value)两部分
- type 包括
static type和concrete type. 简单来说static type是你在编码是看见的类型(如int、string),concrete type是runtime系统看见的类型 - 类型断言能否成功,取决于变量的
concrete type,而不是static type. 因此,一个reader变量如果它的concrete type也实现了write方法的话,它也可以被类型断言为writer.
接下来要讲的反射,就是建立在类型之上的,Golang的指定类型的变量的类型是静态的(也就是指定int、string这些的变量,它的type是static type),在创建变量的时候就已经确定,反射主要与Golang的interface类型相关(它的type是concrete type),只有interface类型才有反射一说。
在Golang的实现中,每个interface变量都有一个对应pair,pair中记录了实际变量的值和类型:
(value, type)
value是实际变量值,type是实际变量的类型。一个interface{}类型的变量包含了2个指针,一个指针指向值的类型【对应concrete type】,另外一个指针指向实际的值【对应value】。
例如,创建类型为*os.File的变量,然后将其赋给一个接口变量r:
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
var r io.Reader
r = tty
接口变量r的pair中将记录如下信息:(tty, *os.File),这个pair在接口变量的连续赋值过程中是不变的,将接口变量r赋给另一个接口变量w:
var w io.Writer
w = r.(io.Writer)
接口变量w的pair与r的pair相同,都是:(tty, *os.File),即使w是空接口类型,pair也是不变的。
interface及其pair的存在,是Golang中实现反射的前提,理解了pair,就更容易理解反射。反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。
package main
import (
"fmt"
"io"
"os"
)
func main() {
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
fmt.Println("open file error", err)
return
}
var r io.Reader
r = tty
var w io.Writer
w = r.(io.Writer)
w.Write([]byte("HELLO THIS IS A TEST!!!\n"))
}
再比如:
package main
import "fmt"
type Reader interface {
ReadBook()
}
type Writer interface {
WriteBook()
}
//具体类型
type Book struct {
}
func (this *Book) ReadBook() {
fmt.Println("Read a book.")
}
func (this *Book) WriteBook() {
fmt.Println("Write a book.")
}
func main() {
b := &Book{}
var r Reader
r = b
r.ReadBook()
var w Writer
w = r.(Writer)
w.WriteBook()
}
# Golang的反射reflect
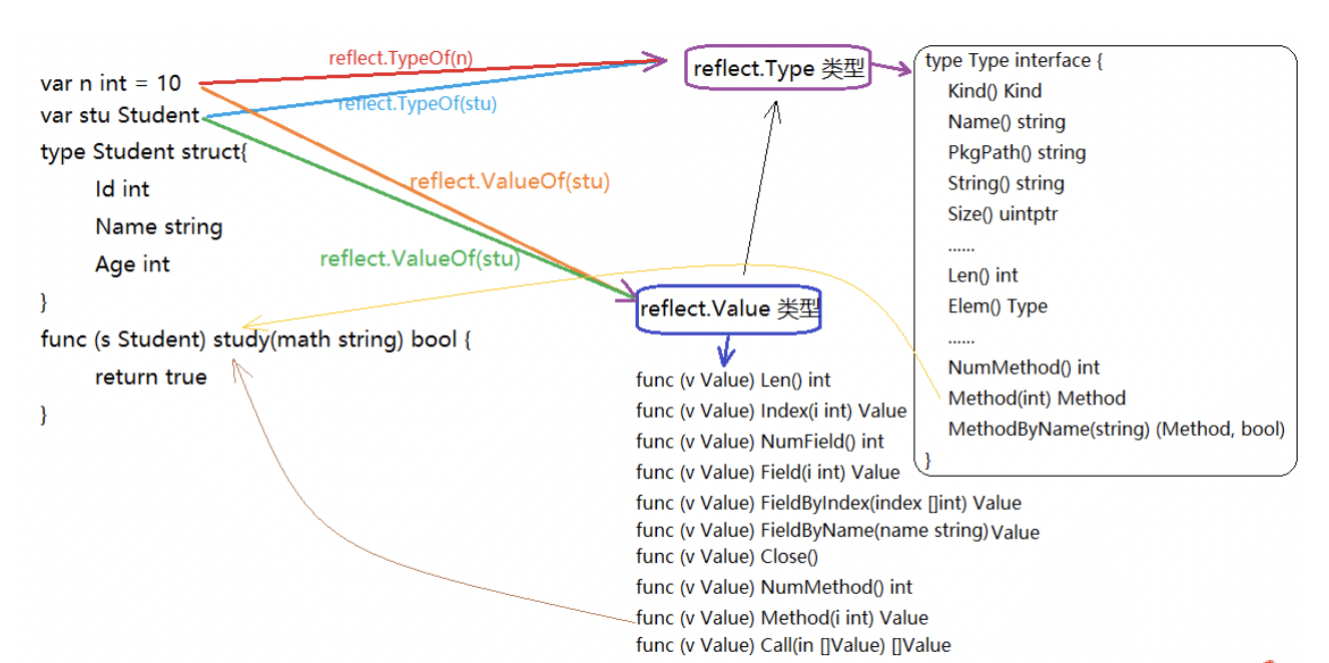
reflect的基本功能TypeOf和ValueOf
既然反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。那么在Golang的reflect反射包中有什么样的方式可以让我们直接获取到变量内部的信息呢? 它提供了两种类型(或者说两个方法)让我们可以很容易的访问接口变量内容,分别是reflect.ValueOf() 和 reflect.TypeOf(),看看官方的解释
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero
func ValueOf(i interface{}) Value {...}
//ValueOf用来获取输入参数接口中的数据的值,如果接口为空则返回0
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {...}
//TypeOf用来动态获取输入参数接口中的值的类型,如果接口为空则返回nil
reflect.TypeOf()是获取pair中的type,reflect.ValueOf()获取pair中的value,示例如下:
package main
import (
"fmt"
"reflect"
)
func main() {
var num float64 = 1.2345
fmt.Println("type: ", reflect.TypeOf(num))
fmt.Println("value: ", reflect.ValueOf(num))
}
运行结果:
type: float64
value: 1.2345
说明
- reflect.TypeOf: 直接给到了我们想要的type类型,如float64、int、各种pointer、struct 等等真实的类型
- reflect.ValueOf:直接给到了我们想要的具体的值,如1.2345这个具体数值,或者类似&{1 "Allen.Wu" 25} 这样的结构体struct的值
- 也就是说明反射可以将“接口类型变量”转换为“反射类型对象”,反射类型指的是reflect.Type和reflect.Value这两种
从relfect.Value中获取接口interface的信息
当执行reflect.ValueOf(interface)之后,就得到了一个类型为”relfect.Value”变量,可以通过它本身的Interface()方法获得接口变量的真实内容,然后可以通过类型判断进行转换,转换为原有真实类型。不过,我们可能是已知原有类型,也有可能是未知原有类型,因此,下面分两种情况进行说明。
已知原有类型【进行“强制转换”】
已知类型后转换为其对应的类型的做法如下,直接通过Interface方法然后强制转换,如下:
realValue := value.Interface().(已知的类型)
示例如下:
package main
import (
"fmt"
"reflect"
)
func main() {
var num float64 = 1.2345
pointer := reflect.ValueOf(&num)
value := reflect.ValueOf(num)
// 可以理解为“强制转换”,但是需要注意的时候,转换的时候,如果转换的类型不完全符合,则直接panic
// Golang 对类型要求非常严格,类型一定要完全符合
// 如下两个,一个是*float64,一个是float64,如果弄混,则会panic
convertPointer := pointer.Interface().(*float64)
convertValue := value.Interface().(float64)
fmt.Println(convertPointer)
fmt.Println(convertValue)
}
运行结果:
0xc42000e238
1.2345
说明
- 转换的时候,如果转换的类型不完全符合,则直接panic,类型要求非常严格!
- 转换的时候,要区分是指针还是指
- 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
未知原有类型【遍历探测其Filed】
很多情况下,我们可能并不知道其具体类型,那么这个时候,该如何做呢?需要我们进行遍历探测其Filed来得知,示例如下:
package main
import (
"fmt"
"reflect"
)
type User struct {
Id int
Name string
Age int
}
func (u User) ReflectCallFunc() {
fmt.Println("Allen.Wu ReflectCallFunc")
}
func main() {
user := User{1, "Allen.Wu", 25}
DoFiledAndMethod(user)
}
// 通过接口来获取任意参数,然后一一揭晓
func DoFiledAndMethod(input interface{}) {
getType := reflect.TypeOf(input)
fmt.Println("get Type is :", getType.Name())
getValue := reflect.ValueOf(input)
fmt.Println("get all Fields is:", getValue)
// 获取方法字段
// 1. 先获取interface的reflect.Type,然后通过NumField进行遍历
// 2. 再通过reflect.Type的Field获取其Field
// 3. 最后通过Field的Interface()得到对应的value
for i := 0; i < getType.NumField(); i++ {
field := getType.Field(i)
value := getValue.Field(i).Interface()
fmt.Printf("%s: %v = %v\n", field.Name, field.Type, value)
}
// 获取方法
// 1. 先获取interface的reflect.Type,然后通过.NumMethod进行遍历
for i := 0; i < getType.NumMethod(); i++ {
m := getType.Method(i)
fmt.Printf("%s: %v\n", m.Name, m.Type)
}
}
运行结果:
get Type is : User
get all Fields is: {1 Allen.Wu 25}
Id: int = 1
Name: string = Allen.Wu
Age: int = 25
ReflectCallFunc: func(main.User)
说明
通过运行结果可以得知获取未知类型的interface的具体变量及其类型的步骤为:
1先获取interface的reflect.Type,然后通过NumField进行遍历
2再通过reflect.Type的Field获取其Field
3最后通过Field的Interface()得到对应的value
通过运行结果可以得知获取未知类型的interface的所属方法(函数)的步骤为:
1先获取interface的reflect.Type,然后通过NumMethod进行遍历
2再分别通过reflect.Type的Method获取对应的真实的方法(函数)
3最后对结果取其Name和Type得知具体的方法名
4也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
5struct 或者 struct 的嵌套都是一样的判断处理方式
# 通过reflect.Value设置实际变量的值
reflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
示例如下:
package main
import (
"fmt"
"reflect"
)
func main() {
var num float64 = 1.2345
fmt.Println("old value of pointer:", num)
// 通过reflect.ValueOf获取num中的reflect.Value,注意,参数必须是指针才能修改其值
pointer := reflect.ValueOf(&num)
newValue := pointer.Elem()
fmt.Println("type of pointer:", newValue.Type())
fmt.Println("settability of pointer:", newValue.CanSet())
// 重新赋值
newValue.SetFloat(77)
fmt.Println("new value of pointer:", num)
////////////////////
// 如果reflect.ValueOf的参数不是指针,会如何?
pointer = reflect.ValueOf(num)
//newValue = pointer.Elem() // 如果非指针,这里直接panic,“panic: reflect: call of reflect.Value.Elem on float64 Value”
}
运行结果:
old value of pointer: 1.2345
type of pointer: float64
settability of pointer: true
new value of pointer: 77
说明
1需要传入的参数是* float64这个指针,然后可以通过pointer.Elem()去获取所指向的Value,注意一定要是指针。
2如果传入的参数不是指针,而是变量,那么
○通过Elem获取原始值对应的对象则直接panic
○通过CanSet方法查询是否可以设置返回false
3newValue.CantSet()表示是否可以重新设置其值,如果输出的是true则可修改,否则不能修改,修改完之后再进行打印发现真的已经修改了。
4reflect.Value.Elem() 表示获取原始值对应的反射对象,只有原始对象才能修改,当前反射对象是不能修改的
5也就是说如果要修改反射类型对象,其值必须是“addressable”【对应的要传入的是指针,同时要通过Elem方法获取原始值对应的反射对象】
6struct 或者 struct 的嵌套都是一样的判断处理方式
# 通过reflect.ValueOf来进行方法的调用
这算是一个高级用法了,前面我们只说到对类型、变量的几种反射的用法,包括如何获取其值、其类型、如果重新设置新值。但是在工程应用中,另外一个常用并且属于高级的用法,就是通过reflect来进行方法【函数】的调用。比如我们要做框架工程的时候,需要可以随意扩展方法,或者说用户可以自定义方法,那么我们通过什么手段来扩展让用户能够自定义呢?关键点在于用户的自定义方法是未可知的,因此我们可以通过reflect来搞定
示例如下:
package main
import (
"fmt"
"reflect"
)
type User struct {
Id int
Name string
Age int
}
func (u User) ReflectCallFuncHasArgs(name string, age int) {
fmt.Println("ReflectCallFuncHasArgs name: ", name, ", age:", age, "and origal User.Name:", u.Name)
}
func (u User) ReflectCallFuncNoArgs() {
fmt.Println("ReflectCallFuncNoArgs")
}
// 如何通过反射来进行方法的调用?
// 本来可以用u.ReflectCallFuncXXX直接调用的,但是如果要通过反射,那么首先要将方法注册,也就是MethodByName,然后通过反射调动mv.Call
func main() {
user := User{1, "Allen.Wu", 25}
// 1. 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value,得到“反射类型对象”后才能做下一步处理
getValue := reflect.ValueOf(user)
// 一定要指定参数为正确的方法名
// 2. 先看看带有参数的调用方法
methodValue := getValue.MethodByName("ReflectCallFuncHasArgs")
args := []reflect.Value{reflect.ValueOf("wudebao"), reflect.ValueOf(30)}
methodValue.Call(args)
// 一定要指定参数为正确的方法名
// 3. 再看看无参数的调用方法
methodValue = getValue.MethodByName("ReflectCallFuncNoArgs")
args = make([]reflect.Value, 0)
methodValue.Call(args)
}
运行结果:
ReflectCallFuncHasArgs name: wudebao , age: 30 and origal User.Name: Allen.Wu
ReflectCallFuncNoArgs
说明
- 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value,得到“反射类型对象”后才能做下一步处理
- reflect.Value.MethodByName这.MethodByName,需要指定准确真实的方法名字,如果错误将直接panic,MethodByName返回一个函数值对应的reflect.Value方法的名字。
- []reflect.Value,这个是最终需要调用的方法的参数,可以没有或者一个或者多个,根据实际参数来定。
- reflect.Value的 Call 这个方法,这个方法将最终调用真实的方法,参数务必保持一致,如果reflect.Value'Kind不是一个方法,那么将直接panic。
- 本来可以用u.ReflectCallFuncXXX直接调用的,但是如果要通过反射,那么首先要将方法注册,也就是MethodByName,然后通过反射调用methodValue.Call
# Golang的反射reflect性能
Golang的反射很慢,这个和它的API设计有关。在 java 里面,我们一般使用反射都是这样来弄的。
Field field = clazz.getField("hello");
field.get(obj1);
field.get(obj2);
但是Golang的反射不是这样设计的:
type_ := reflect.TypeOf(obj)
field, _ := type_.FieldByName("hello")
这里取出来的 field 对象是 reflect.StructField 类型,但是它没有办法用来取得对应对象上的值。如果要取值,得用另外一套对object,而不是type的反射
type_ := reflect.ValueOf(obj)
fieldValue := type_.FieldByName("hello")
这里取出来的 fieldValue 类型是 reflect.Value,它是一个具体的值,而不是一个可复用的反射对象了,每次反射都需要malloc这个reflect.Value结构体,并且还涉及到GC。
Golang reflect慢主要有两个原因
涉及到内存分配以及后续的GC;
reflect实现里面有大量的枚举,也就是for循环,比如类型之类的.
# 总结
上述详细说明了Golang的反射reflect的各种功能和用法,都附带有相应的示例,相信能够在工程应用中进行相应实践,总结一下就是:
反射可以大大提高程序的灵活性,使得interface{}有更大的发挥余地
- 反射必须结合interface才玩得转
- 变量的type要是concrete type的(也就是interface变量)才有反射一说
反射可以将“接口类型变量”转换为“反射类型对象”
- 反射使用 TypeOf 和 ValueOf 函数从接口中获取目标对象信息
反射可以将“反射类型对象”转换为“接口类型变量
- reflect.value.Interface().(已知的类型)
- 遍历reflect.Type的Field获取其Field
反射可以修改反射类型对象,但是其值必须是“addressable”
- 想要利用反射修改对象状态,前提是 interface.data 是 settable,即 pointer-interface
通过反射可以“动态”调用方法
因为Golang本身不支持模板,因此在以往需要使用模板的场景下往往就需要使用反射(reflect)来实现
# 反射的基本原理
# 结构体标签
package main
import (
"fmt"
"reflect"
)
type resume struct {
Name string `json:"name" doc:"我的名字"`
}
func findDoc(stru interface{}) map[string]string {
t := reflect.TypeOf(stru).Elem()
doc := make(map[string]string)
for i := 0; i < t.NumField(); i++ {
doc[t.Field(i).Tag.Get("json")] = t.Field(i).Tag.Get("doc")
}
return doc
}
func main() {
var stru resume
doc := findDoc(&stru)
fmt.Printf("name字段为:%s\n", doc["name"])
}
# 五、高阶
# Go Modules
# A、什么是Go Modules?
Go modules 是 Go 语言的依赖解决方案,发布于 Go1.11,成长于 Go1.12,丰富于 Go1.13,正式于 Go1.14 推荐在生产上使用。
Go moudles 目前集成在 Go 的工具链中,只要安装了 Go,自然而然也就可以使用 Go moudles 了,而 Go modules 的出现也解决了在 Go1.11 前的几个常见争议问题:
- Go 语言长久以来的依赖管理问题。
- “淘汰”现有的 GOPATH 的使用模式。
- 统一社区中的其它的依赖管理工具(提供迁移功能)。
# B、GOPATH的工作模式
Go Modoules的目的之一就是淘汰GOPATH, 那么GOPATH是个什么?
为什么在 Go1.11 前就使用 GOPATH,而 Go1.11 后就开始逐步建议使用 Go modules,不再推荐 GOPATH 的模式了呢?
# (1) Wait is GOPATH?
$ go env
GOPATH="/home/itheima/go"
...
我们输入go env命令行后可以查看到 GOPATH 变量的结果,我们进入到该目录下进行查看,如下:
go
├── bin
├── pkg
└── src
├── github.com
├── golang.org
├── google.golang.org
├── gopkg.in
....
GOPATH目录下一共包含了三个子目录,分别是:
- bin:存储所编译生成的二进制文件。
- pkg:存储预编译的目标文件,以加快程序的后续编译速度。
- src:存储所有
.go文件或源代码。在编写 Go 应用程序,程序包和库时,一般会以$GOPATH/src/github.com/foo/bar的路径进行存放。
因此在使用 GOPATH 模式下,我们需要将应用代码存放在固定的$GOPATH/src目录下,并且如果执行go get来拉取外部依赖会自动下载并安装到$GOPATH目录下。
# (2) GOPATH模式的弊端
在 GOPATH 的 $GOPATH/src 下进行 .go 文件或源代码的存储,我们可以称其为 GOPATH 的模式,这个模式拥有一些弊端.
A. 无版本控制概念. 在执行
go get的时候,你无法传达任何的版本信息的期望,也就是说你也无法知道自己当前更新的是哪一个版本,也无法通过指定来拉取自己所期望的具体版本。B.无法同步一致第三方版本号. 在运行 Go 应用程序的时候,你无法保证其它人与你所期望依赖的第三方库是相同的版本,也就是说在项目依赖库的管理上,你无法保证所有人的依赖版本都一致。
C.无法指定当前项目引用的第三方版本号. 你没办法处理 v1、v2、v3 等等不同版本的引用问题,因为 GOPATH 模式下的导入路径都是一样的,都是
github.com/foo/bar。
# C、Go Modules模式
我们接下来用Go Modules的方式创建一个项目, 建议为了与GOPATH分开,不要将项目创建在GOPATH/src下.
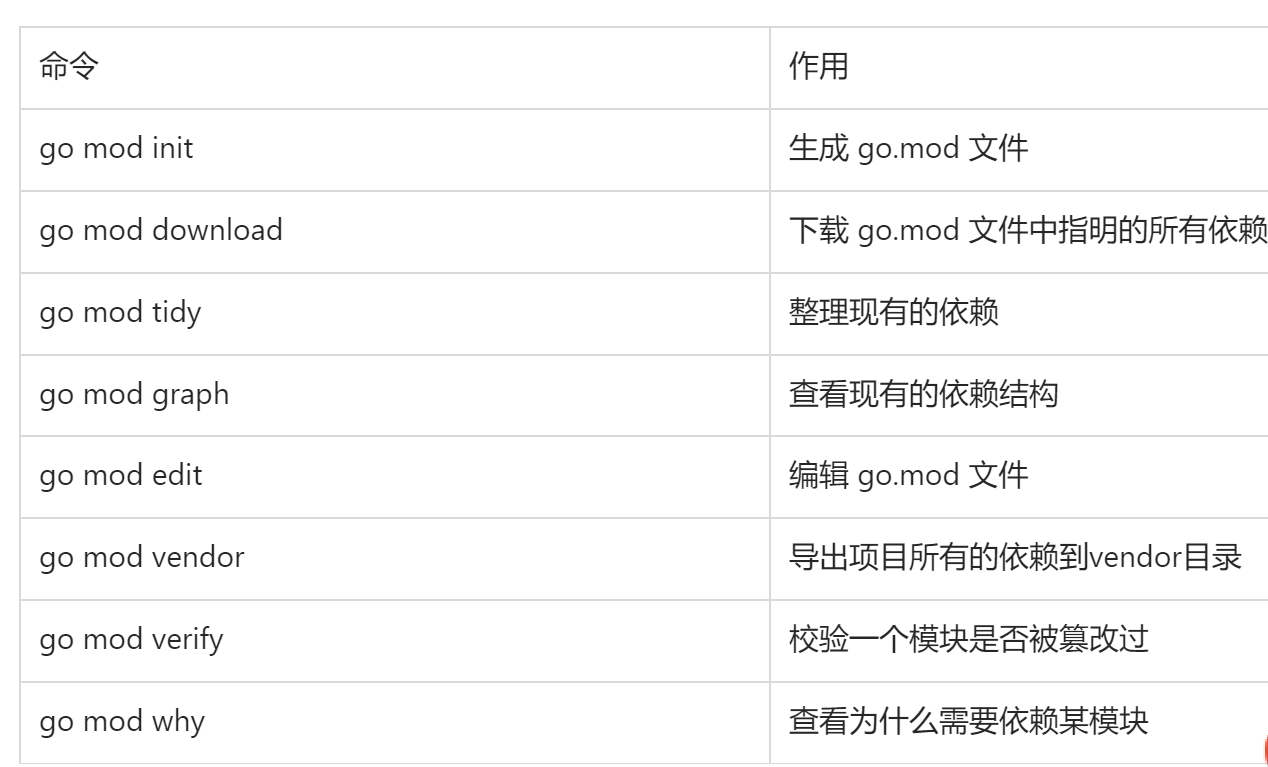
# (1) go mod命令
# (2) go mod环境变量
可以通过 go env 命令来进行查看

$ go env
GO111MODULE="auto"
GOPROXY="https://proxy.golang.org,direct"
GONOPROXY=""
GOSUMDB="sum.golang.org"
GONOSUMDB=""
GOPRIVATE=""
...
# GO111MODULE
Go语言提供了 GO111MODULE这个环境变量来作为 Go modules 的开关,其允许设置以下参数:
- auto:只要项目包含了 go.mod 文件的话启用 Go modules,目前在 Go1.11 至 Go1.14 中仍然是默认值。
- on:启用 Go modules,推荐设置,将会是未来版本中的默认值。
- off:禁用 Go modules,不推荐设置。
可以通过来设置
$ go env -w GO111MODULE=on
# GOPROXY
这个环境变量主要是用于设置 Go 模块代理(Go module proxy),其作用是用于使 Go 在后续拉取模块版本时直接通过镜像站点来快速拉取。
GOPROXY 的默认值是:https://proxy.golang.org,direct
proxy.golang.org国内访问不了,需要设置国内的代理.
- 阿里云 https://mirrors.aliyun.com/goproxy/
- 七牛云 https://goproxy.cn,direct
如:
$ go env -w GOPROXY=https://goproxy.cn,direct
GOPROXY 的值是一个以英文逗号 “,” 分割的 Go 模块代理列表,允许设置多个模块代理,假设你不想使用,也可以将其设置为 “off” ,这将会禁止 Go 在后续操作中使用任何 Go 模块代理。
如:
$ go env -w GOPROXY=https://goproxy.cn,https://mirrors.aliyun.com/goproxy/,direct
direct
而在刚刚设置的值中,我们可以发现值列表中有 “direct” 标识,它又有什么作用呢?
实际上 “direct” 是一个特殊指示符,用于指示 Go 回源到模块版本的源地址去抓取(比如 GitHub 等),场景如下:当值列表中上一个 Go 模块代理返回 404 或 410 错误时,Go 自动尝试列表中的下一个,遇见 “direct” 时回源,也就是回到源地址去抓取,而遇见 EOF 时终止并抛出类似 “invalid version: unknown revision...” 的错误。
# 修改goproxy
$env:GOPROXY = "https://goproxy.cn,direct"
# GOSUMDB
它的值是一个 Go checksum database,用于在拉取模块版本时(无论是从源站拉取还是通过 Go module proxy 拉取)保证拉取到的模块版本数据未经过篡改,若发现不一致,也就是可能存在篡改,将会立即中止。
GOSUMDB 的默认值为:sum.golang.org,在国内也是无法访问的,但是 GOSUMDB 可以被 Go 模块代理所代理(详见:Proxying a Checksum Database)。
因此我们可以通过设置 GOPROXY 来解决,而先前我们所设置的模块代理 goproxy.cn 就能支持代理 sum.golang.org,所以这一个问题在设置 GOPROXY 后,你可以不需要过度关心。
另外若对 GOSUMDB 的值有自定义需求,其支持如下格式:
- 格式 1:
<SUMDB_NAME>+<PUBLIC_KEY>。 - 格式 2:
<SUMDB_NAME>+<PUBLIC_KEY> <SUMDB_URL>。
也可以将其设置为“off”,也就是禁止 Go 在后续操作中校验模块版本。
# GONOPROXY/GONOSUMDB/GOPRIVATE
这三个环境变量都是用在当前项目依赖了私有模块,例如像是你公司的私有 git 仓库,又或是 github 中的私有库,都是属于私有模块,都是要进行设置的,否则会拉取失败。
更细致来讲,就是依赖了由 GOPROXY 指定的 Go 模块代理或由 GOSUMDB 指定 Go checksum database 都无法访问到的模块时的场景。
而一般建议直接设置 GOPRIVATE,它的值将作为 GONOPROXY 和 GONOSUMDB 的默认值,所以建议的最佳姿势是直接使用 GOPRIVATE。
并且它们的值都是一个以英文逗号 “,” 分割的模块路径前缀,也就是可以设置多个,例如:
$ go env -w GOPRIVATE="git.example.com,github.com/eddycjy/mquote"
设置后,前缀为 git.xxx.com 和 github.com/eddycjy/mquote 的模块都会被认为是私有模块。
如果不想每次都重新设置,我们也可以利用通配符,例如:
$ go env -w GOPRIVATE="*.example.com"
这样子设置的话,所有模块路径为 example.com 的子域名(例如:git.example.com)都将不经过 Go module proxy 和 Go checksum database,需要注意的是不包括 example.com 本身。
# D、使用Go Modules初始化项目
# (1) 开启Go Modules
$ go env -w GO111MODULE=on
又或是可以通过直接设置系统环境变量(写入对应的~/.bash_profile 文件亦可)来实现这个目的:
$ export GO111MODULE=on
# (2) 初始化项目
创建项目目录
$ mkdir -p $HOME/aceld/modules_test
$ cd $HOME/aceld/modules_test
执行Go modules 初始化
$ go mod init github.com/aceld/modules_test
go: creating new go.mod: module github.com/aceld/modules_test
在执行 go mod init 命令时,我们指定了模块导入路径为 github.com/aceld/modules_test。接下来我们在该项目根目录下创建 main.go 文件,如下:
package main
import (
"fmt"
"github.com/aceld/zinx/znet"
"github.com/aceld/zinx/ziface"
)
//ping test 自定义路由
type PingRouter struct {
znet.BaseRouter
}
//Ping Handle
func (this *PingRouter) Handle(request ziface.IRequest) {
//先读取客户端的数据
fmt.Println("recv from client : msgId=", request.GetMsgID(),
", data=", string(request.GetData()))
//再回写ping...ping...ping
err := request.GetConnection().SendBuffMsg(0, []byte("ping...ping...ping"))
if err != nil {
fmt.Println(err)
}
}
func main() {
//1 创建一个server句柄
s := znet.NewServer()
//2 配置路由
s.AddRouter(0, &PingRouter{})
//3 开启服务
s.Serve()
}
OK, 我们先不要关注代码本身,我们看当前的main.go也就是我们的aceld/modules_test项目,是依赖一个叫github.com/aceld/zinx库的. znet和ziface只是zinx的两个模块.
接下来我们在$HOME/aceld/modules_test,本项目的根目录执行
$ go get github.com/aceld/zinx/znet
go: downloading github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100
go: found github.com/aceld/zinx/znet in github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100
我们会看到 我们的go.mod被修改,同时多了一个go.sum文件.
# (3) 查看go.mod文件
aceld/modules_test/go.mod
module github.com/aceld/modules_test
go 1.14
require github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100 // indirect
我们来简单看一下这里面的关键字
module: 用于定义当前项目的模块路径
go:标识当前Go版本.即初始化版本
require: 当前项目依赖的一个特定的必须版本
// indirect: 示该模块为间接依赖,也就是在当前应用程序中的 import 语句中,并没有发现这个模块的明确引用,有可能是你先手动 go get 拉取下来的,也有可能是你所依赖的模块所依赖的.我们的代码很明显是依赖的"github.com/aceld/zinx/znet"和"github.com/aceld/zinx/ziface",所以就间接的依赖了github.com/aceld/zinx
# (4) 查看go.sum文件
在第一次拉取模块依赖后,会发现多出了一个 go.sum 文件,其详细罗列了当前项目直接或间接依赖的所有模块版本,并写明了那些模块版本的 SHA-256 哈希值以备 Go 在今后的操作中保证项目所依赖的那些模块版本不会被篡改
github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100 h1:Ez5iM6cKGMtqvIJ8nvR9h74Ln8FvFDgfb7bJIbrKv54=
github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100/go.mod h1:bMiERrPdR8FzpBOo86nhWWmeHJ1cCaqVvWKCGcDVJ5M=
github.com/golang/protobuf v1.3.3/go.mod h1:vzj43D7+SQXF/4pzW/hwtAqwc6iTitCiVSaWz5lYuqw=
我们可以看到一个模块路径可能有如下两种:
h1:hash情况
github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100 h1:Ez5iM6cKGMtqvIJ8nvR9h74Ln8FvFDgfb7bJIbrKv54=
go.mod hash情况
github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100/go.mod h1:bMiERrPdR8FzpBOo86nhWWmeHJ1cCaqVvWKCGcDVJ5M=
github.com/golang/protobuf v1.3.3/go.mod h1:vzj43D7+SQXF/4pzW/hwtAqwc6iTitCiVSaWz5lYuqw=
h1 hash 是 Go modules 将目标模块版本的 zip 文件开包后,针对所有包内文件依次进行 hash,然后再把它们的 hash 结果按照固定格式和算法组成总的 hash 值。
而 h1 hash 和 go.mod hash 两者,要不就是同时存在,要不就是只存在 go.mod hash。那什么情况下会不存在 h1 hash 呢,就是当 Go 认为肯定用不到某个模块版本的时候就会省略它的 h1 hash,就会出现不存在 h1 hash,只存在 go.mod hash 的情况。
# E、修改模块的版本依赖关系
为了作尝试,假定我们现在都zinx版本作了升级, 由zinx v0.0.0-20200221135252-8a8954e75100 升级到 zinx v0.0.0-20200306023939-bc416543ae24 (注意zinx是一个没有打版本tag打第三方库,如果有的版本号是有tag的,那么可以直接对应v后面的版本号即可)
那么,我们是怎么知道zinx做了升级呢, 我们又是如何知道的最新的zinx版本号是多少呢?
先回到$HOME/aceld/modules_test,本项目的根目录执行
$ go get github.com/aceld/zinx/znet
go: downloading github.com/aceld/zinx v0.0.0-20200306023939-bc416543ae24
go: found github.com/aceld/zinx/znet in github.com/aceld/zinx v0.0.0-20200306023939-bc416543ae24
go: github.com/aceld/zinx upgrade => v0.0.0-20200306023939-bc416543ae24
这样我们,下载了最新的zinx, 版本是v0.0.0-20200306023939-bc416543ae24
然后,我么看一下go.mod
module github.com/aceld/modules_test
go 1.14
require github.com/aceld/zinx v0.0.0-20200306023939-bc416543ae24 // indirect
我们会看到,当我们执行go get 的时候, 会自动的将本地将当前项目的require更新了.变成了最新的依赖.
好了, 现在我们就要做另外一件事,就是,我们想用一个旧版本的zinx. 来修改当前zinx模块的依赖版本号.
目前我们在$GOPATH/pkg/mod/github.com/aceld下,已经有了两个版本的zinx库
/go/pkg/mod/github.com/aceld$ ls
zinx@v0.0.0-20200221135252-8a8954e75100
zinx@v0.0.0-20200306023939-bc416543ae24
目前,我们/aceld/modules_test依赖的是[email protected] 这个是最新版, 我们要改成之前的版本[email protected].
回到/aceld/modules_test项目目录下,执行
$ go mod edit -replace=zinx@v0.0.0-20200306023939-bc416543ae24=zinx@v0.0.0-20200221135252-8a8954e75100
然后我们打开go.mod查看一下
module github.com/aceld/modules_test
go 1.14
require github.com/aceld/zinx v0.0.0-20200306023939-bc416543ae24 // indirect
replace zinx v0.0.0-20200306023939-bc416543ae24 => zinx v0.0.0-20200221135252-8a8954e75100
这里出现了replace关键字.用于将一个模块版本替换为另外一个模块版本。
# goroutine
# 协程并发
协程:coroutine。也叫轻量级线程。
与传统的系统级线程和进程相比,协程最大的优势在于“轻量级”。可以轻松创建上万个而不会导致系统资源衰竭。而线程和进程通常很难超过1万个。这也是协程别称“轻量级线程”的原因。
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
多数语言在语法层面并不直接支持协程,而是通过库的方式支持,但用库的方式支持的功能也并不完整,比如仅仅提供协程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
在协程中,调用一个任务就像调用一个函数一样,消耗的系统资源最少!但能达到进程、线程并发相同的效果。
在一次并发任务中,进程、线程、协程均可以实现。从系统资源消耗的角度出发来看,进程相当多,线程次之,协程最少。
# Go并发
Go 在语言级别支持协程,叫goroutine。Go 语言标准库提供的所有系统调用操作(包括所有同步IO操作),都会出让CPU给其他goroutine。这让轻量级线程的切换管理不依赖于系统的线程和进程,也不需要依赖于CPU的核心数量。
有人把Go比作21世纪的C语言。第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持并发。同时,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制。
Go语言为并发编程而内置的上层API基于顺序通信进程模型CSP(communicating sequential processes)。这就意味着显式锁都是可以避免的,因为Go通过相对安全的通道发送和接受数据以实现同步,这大大地简化了并发程序的编写。
Go语言中的并发程序主要使用两种手段来实现。goroutine和channel。
# 什么是Goroutine
goroutine是Go语言并行设计的核心,有人称之为go程。 Goroutine从量级上看很像协程,它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
一般情况下,一个普通计算机跑几十个线程就有点负载过大了,但是同样的机器却可以轻松地让成百上千个goroutine进行资源竞争。
# 创建Goroutine
只需在函数调⽤语句前添加 go 关键字,就可创建并发执⾏单元。开发⼈员无需了解任何执⾏细节,调度器会自动将其安排到合适的系统线程上执行。
在并发编程中,我们通常想将一个过程切分成几块,然后让每个goroutine各自负责一块工作,当一个程序启动时,主函数在一个单独的goroutine中运行,我们叫它main goroutine。新的goroutine会用go语句来创建。而go语言的并发设计,让我们很轻松就可以达成这一目的。
示例代码:
package main
import (
"fmt"
"time"
)
func newTask() {
i := 0
for {
i++
fmt.Printf("new goroutine: i = %d\n", i)
time.Sleep(1*time.Second) //延时1s
}
}
func main() {
//创建一个 goroutine,启动另外一个任务
go newTask()
i := 0
//main goroutine 循环打印
for {
i++
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(1 * time.Second) //延时1s
}
}
程序运行结果:

# Goroutine特性
主goroutine退出后,其它的工作goroutine也会自动退出:
package main
import (
"fmt"
"time"
)
func newTask() {
i := 0
for {
i++
fmt.Printf("new goroutine: i = %d\n", i)
time.Sleep(1 * time.Second) //延时1s
}
}
func main() {
//创建一个 goroutine,启动另外一个任务
go newTask()
fmt.Println("main goroutine exit")
}
程序运行结果:

# Goexit函数
调用 runtime.Goexit() 将立即终止当前 goroutine 执⾏,调度器确保所有已注册 defer 延迟调用被执行。
示例代码:
package main
import (
"fmt"
"runtime"
)
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit() // 终止当前 goroutine, import "runtime"
fmt.Println("B") // 不会执行
}()
fmt.Println("A") // 不会执行
}() //不要忘记()
//死循环,目的不让主goroutine结束
for {
}
}
程序运行结果:

# channel
channel是Go语言中的一个核心类型,可以把它看成管道。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。
channel是一个数据类型,主要用来解决go程的同步问题以及go程之间数据共享(数据传递)的问题。
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
# 定义channel变量
和map类似,channel也一个对应make创建的底层数据结构的引用。
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建:
chan是创建channel所需使用的关键字。Type 代表指定channel收发数据的类型。
make(chan Type) //等价于make(chan Type, 0)
make(chan Type, capacity)
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
当 参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
channel非常像生活中的管道,一边可以存放东西,另一边可以取出东西。channel通过操作符 <- 来接收和发送数据,发送和接收数据语法:
channel <- value //发送value到channel
<-channel //接收并将其丢弃
x := <-channel //从channel中接收数据,并赋值给x
x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空
默认情况下,channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得goroutine同步变的更加的简单,而不需要显式的lock。
示例代码:
package main
import (
"fmt"
)
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子go程结束")
fmt.Println("子go程正在运行……")
c <- 666 //666发送到c
}()
num := <-c //从c中接收数据,并赋值给num
fmt.Println("num = ", num)
fmt.Println("main go程结束")
}
程序运行结果:

# 无缓冲的channel
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何数据值的通道。
这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。否则,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
**阻塞:**由于某种原因数据没有到达,当前go程(线程)持续处于等待状态,直到条件满足,才解除阻塞。
**同步:**在两个或多个go程(线程)间,保持数据内容一致性的机制。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值:
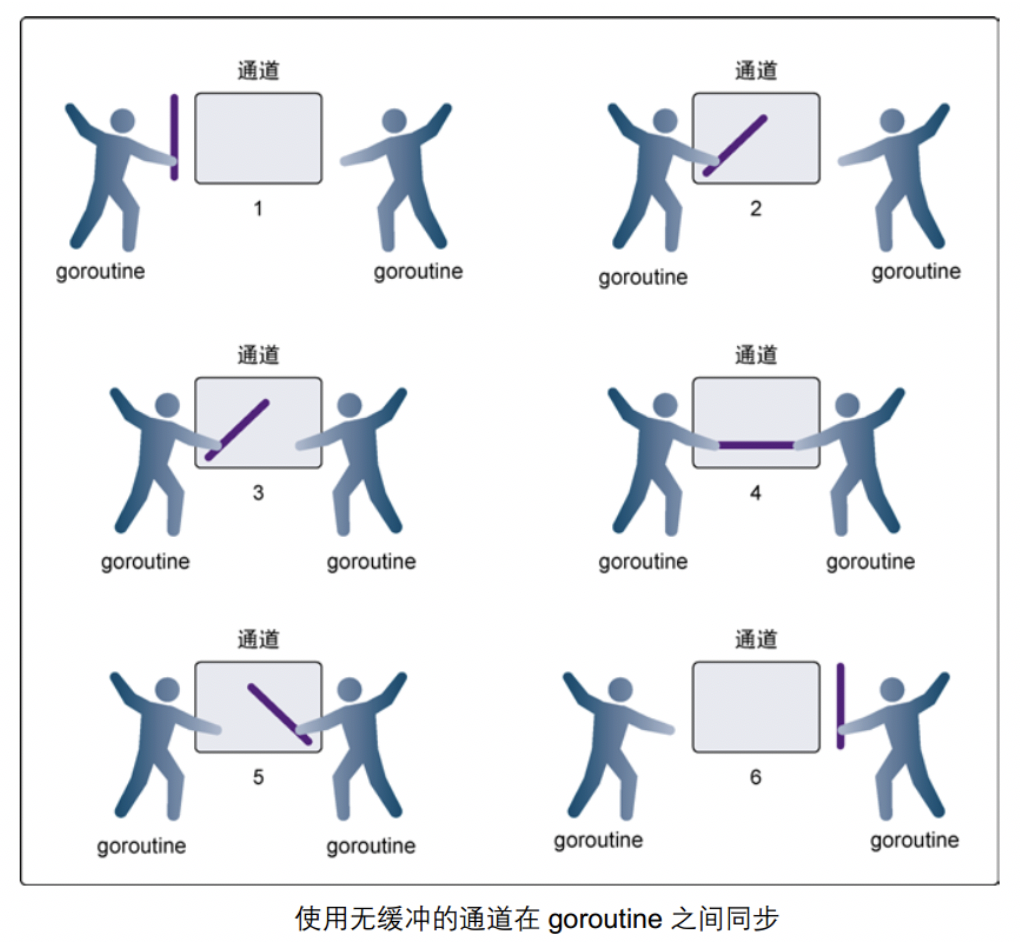
在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
● 在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
● 在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
● 在第 4 步和第 5 步,进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做其他事情了。
无缓冲的channel创建格式:
make(chan Type) //等价于make(chan Type, 0)
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
示例代码:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan int, 0) //创建无缓冲的通道 c
//内置函数 len 返回未被读取的缓冲元素数量,cap 返回缓冲区大小
fmt.Printf("len(c)=%d, cap(c)=%d\n", len(c), cap(c))
go func() {
defer fmt.Println("子go程结束")
for i := 0; i < 3; i++ {
c <- i
fmt.Printf("子go程正在运行[%d]: len(c)=%d, cap(c)=%d\n", i, len(c), cap(c))
}
}()
time.Sleep(2 * time.Second) //延时2s
for i := 0; i < 3; i++ {
num := <-c //从c中接收数据,并赋值给num
fmt.Println("num = ", num)
}
fmt.Println("main进程结束")
}
程序运行结果:

# 有缓冲的channel
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道。
这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也不同。
只有通道中没有要接收的值时,接收动作才会阻塞。
只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
示例图如下:
通道
通道
2
GOROUTINE
GOROUTINE
GOROUTINE
GOROUTINE
通道
通道
3
GOROUTINE
GOROUTINE
GOROUTINE
GOROUTINE
使用有缓冲的通道在GOROUTINE之间同步数据
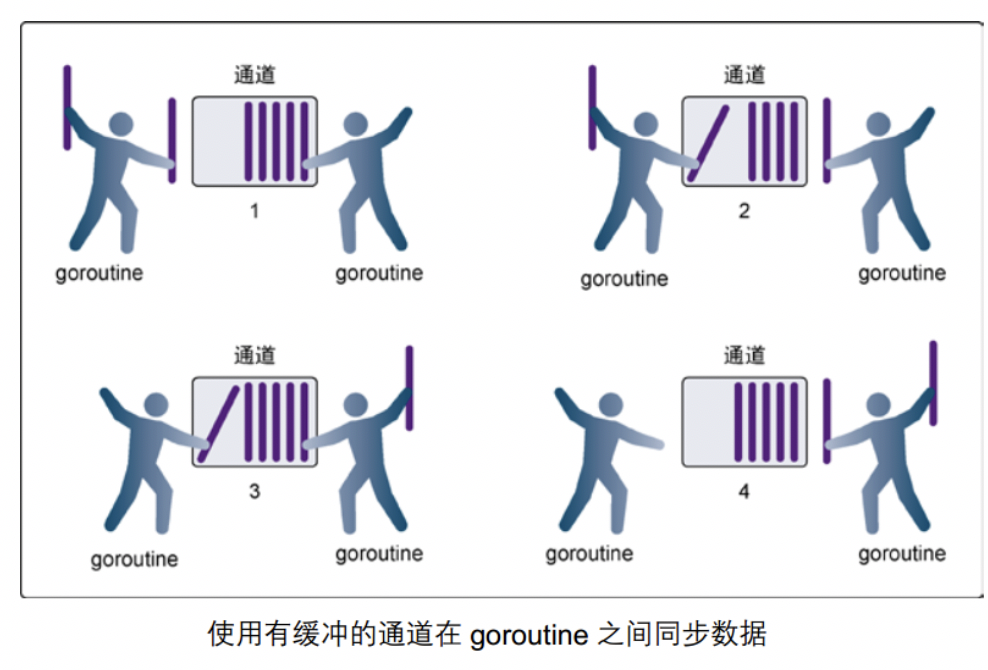
图片为转载
● 在第 1 步,右侧的 goroutine 正在从通道接收一个值。
● 在第 2 步,右侧的这个 goroutine独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。
● 在第 3 步,左侧的goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。
● 最后,在第 4 步,所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。
有缓冲的channel创建格式:
make(chan Type, capacity)
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
借助函数 len(ch) 求取缓冲区中剩余元素个数, cap(ch) 求取缓冲区元素容量大小。
示例代码:
func main() {
c := make(chan int, 3) //带缓冲的通道
//内置函数 len 返回未被读取的缓冲元素数量, cap 返回缓冲区大小
fmt.Printf("len(c)=%d, cap(c)=%d\n", len(c), cap(c))
go func() {
defer fmt.Println("子go程结束")
for i := 0; i < 3; i++ {
c <- i
fmt.Printf("子go程正在运行[%d]: len(c)=%d, cap(c)=%d\n", i, len(c), cap(c))
}
}()
time.Sleep(2 * time.Second) //延时2s
for i := 0; i < 3; i++ {
num := <-c //从c中接收数据,并赋值给num
fmt.Println("num = ", num)
}
fmt.Println("main进程结束")
}
程序运行结果:

# 关闭channel
如果发送者知道,没有更多的值需要发送到channel的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close函数来关闭channel实现。
示例代码:
package main
import (
"fmt"
)
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
close(c)
}()
for {
//ok为true说明channel没有关闭,为false说明管道已经关闭
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("Finished")
}
程序运行结果:

注意:
l channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的,才去关闭channel;
l 关闭channel后,无法向channel 再发送数据(引发 panic 错误后导致接收立即返回零值);
l 关闭channel后,可以继续从channel接收数据;
l 对于nil channel,无论收发都会被阻塞。
可以使用 range 来迭代不断操作channel:
package main
import (
"fmt"
)
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
close(c)
}()
for data := range c {
fmt.Println(data)
}
fmt.Println("Finished")
}
# 单向channel及应用
默认情况下,通道channel是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而只希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。

单向channel变量的声明非常简单,如下:
var ch1 chan int // ch1是一个正常的channel,是双向的
var ch2 chan<- float64 // ch2是单向channel,只用于写float64数据
var ch3 <-chan int // ch3是单向channel,只用于读int数据
l chan<- 表示数据进入管道,要把数据写进管道,对于调用者就是输出。
l <-chan 表示数据从管道出来,对于调用者就是得到管道的数据,当然就是输入。
可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为普通 channel:
c := make(chan int, 3)
var send chan<- int = c // send-only
var recv <-chan int = c // receive-only
send <- 1
//<-send //invalid operation: <-send (receive from send-only type chan<- int)
<-recv
//recv <- 2 //invalid operation: recv <- 2 (send to receive-only type <-chan int)
//不能将单向 channel 转换为普通 channel
d1 := (chan int)(send) //cannot convert send (type chan<- int) to type chan int
d2 := (chan int)(recv) //cannot convert recv (type <-chan int) to type chan int
示例代码:
// chan<- //只写
func counter(out chan<- int) {
defer close(out)
for i := 0; i < 5; i++ {
out <- i //如果对方不读 会阻塞
}
}
// <-chan //只读
func printer(in <-chan int) {
for num := range in {
fmt.Println(num)
}
}
func main() {
c := make(chan int) // chan //读写
go counter(c) //生产者
printer(c) //消费者
fmt.Println("done")
}
# Select
# select作用
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
有时候我们希望能够借助channel发送或接收数据,并避免因为发送或者接收导致的阻塞,尤其是当channel没有准备好写或者读时。select语句就可以实现这样的功能。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
与switch语句相比,select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作,大致的结构如下:
select {
case <- chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
在一个select语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况:
l 如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。
l 如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以进行下去。
示例代码:
package main
import (
"fmt"
)
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
运行结果如下:

若有收获,就点个赞吧